Retrieval-Augmented Generation - RAG
EEnhance your AI with accurate, up-to-date information from your own (private/company) knowledge base using state-of-the-art RAG architecture. Our solutions leverage vector embeddings, semantic search, and large language models to deliver precise, context-aware responses. We support multi-hop retrieval and streaming RAG for faster, more comprehensive answers across complex documents. Easily integrate with popular vector databases like Weaviate, Qdrant, pgvector and FAISS—optimized for scale, security, and real-time updates.
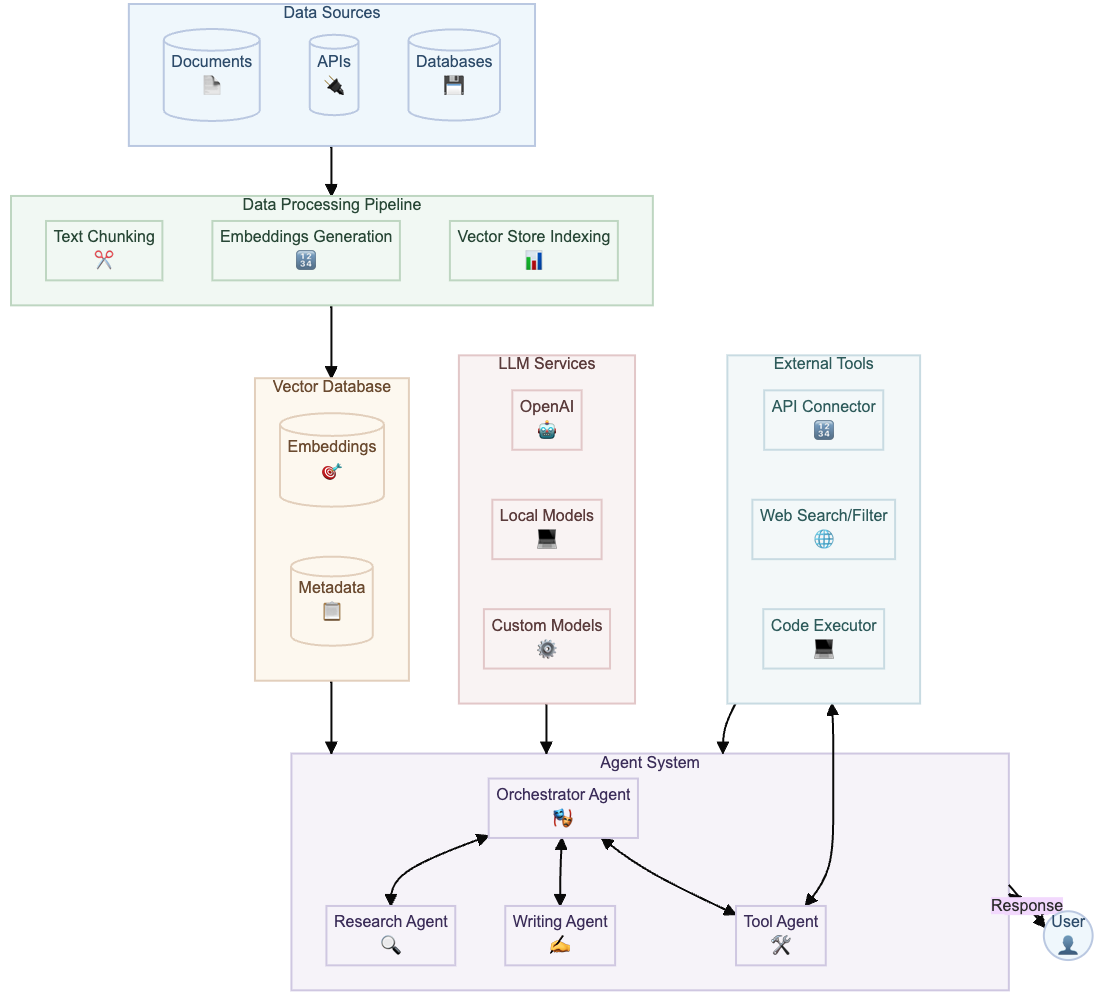
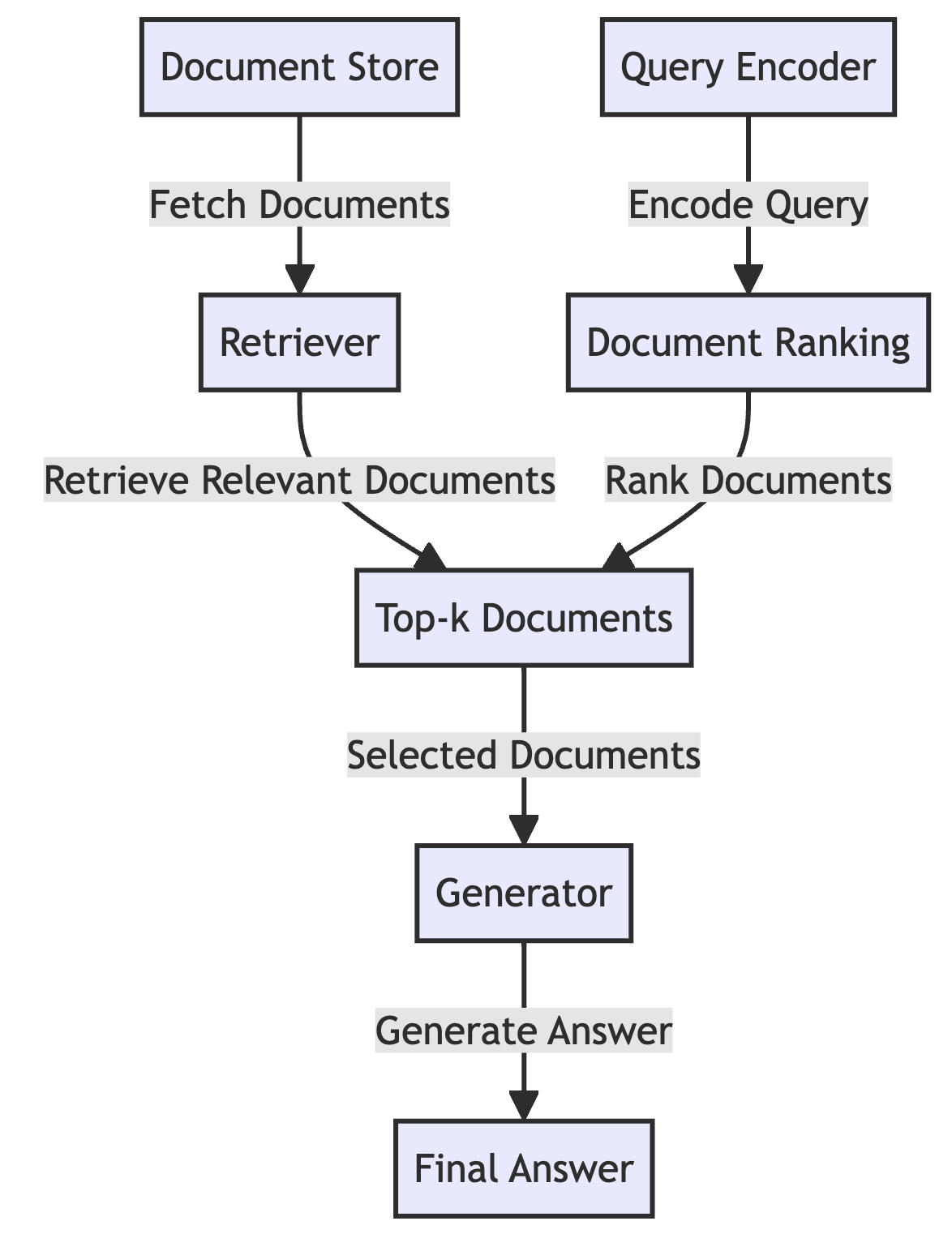
What is Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) is an advanced AI framework that enhances large language models (LLMs) by integrating them with external knowledge retrieval systems. While LLMs excel at generating responses based on general knowledge, RAG extends their capabilities by dynamically accessing and incorporating up-to-date information from external sources. RAG had its peak in 2023 and 2024 but it remains relevant as a cornerstone of a LLM-solution.
Core Components:
- Retriever: Efficiently searches and retrieves relevant information from knowledge bases using vector similarity search
- Generator: Processes the retrieved context to generate accurate, well-grounded responses
- Vector Database: Stores document embeddings for fast semantic search and retrieval
Technical Advantages:
- Reduced hallucination through evidence-based generation
- Improved accuracy with source attribution
- Dynamic knowledge updates without model retraining
- Efficient handling of domain-specific knowledge
How RAG Works
Our RAG implementation follows a sophisticated, multi-stage pipeline designed for maximum accuracy and performance
Document Processing
- Text Extraction: PDFs, DOCs, HTML, and more
- Semantic Chunking: Context-aware text segmentation
- Embedding: Transformers (e.g., BERT, RoBERTa, MPNet)
- Storage: Vector databases (Pinecone, Weaviate, FAISS)
Query Processing
- Query Expansion: Generate multiple query variations
- Hybrid Search: Combine BM25 + Dense Retrieval
- Re-ranking: Cross-encoders for precision
- Context Assembly: Dynamic context window management
Generation & Enhancement
- Prompt Engineering: Chain-of-thought, few-shot examples
- Source Attribution: Verifiable citations and references
- Confidence Scoring: Uncertainty estimation
- Post-processing: Formatting, filtering, and safety checks
Continuous Improvement
- Feedback Loop: Explicit and implicit feedback collection
- Active Learning: Identify knowledge gaps
- Model Updates: Continuous retraining pipeline
- Monitoring: Performance metrics and drift detection
Why Choose RAG?
Key advantages of our RAG implementation for enterprise applications
Precision & Accuracy
Dramatically reduce hallucinations by grounding responses in your specific knowledge base with verifiable sources.
Always Current
Keep your AI's knowledge up-to-date by simply updating your document store, no retraining required.
Source Transparency
Every response includes source attribution, enabling verification and building trust with users.
Data Privacy
Keep sensitive data in-house with private knowledge bases and on-premise deployment options.
Performance
Optimized retrieval and generation pipelines for low-latency, high-throughput production deployments.
Customization
Tailor the system to your specific domain with custom embeddings, retrieval strategies, and prompts.
Technical Deep Dive
Advanced RAG Architecture
Vector Embedding Models
- Transformer-based models (BERT, RoBERTa, etc.)
- Sparse vs. Dense embeddings
- Fine-tuning for domain adaptation
Retrieval Optimization
- Hybrid search (BM25 + Dense retrieval)
- Query expansion and rewriting
- Reranking with cross-encoders
Generation Enhancement
- Prompt engineering techniques
- Context compression
- Multi-step reasoning
Vector Database Technology
Vector Databases in RAG
Vector databases enable efficient similarity search in high-dimensional spaces, making them ideal for RAG implementations. They store and retrieve vector embeddings generated by transformer models.
Key Components:
- Example: pgvector: PostgreSQL extension for vector similarity search
- HNSW (Hierarchical Navigable Small World): Fast approximate nearest neighbor search
- Quantization: Reduces vector dimensions while preserving similarity
Optimization Techniques:
Indexing
IVFFlat, HNSW, and LSH for efficient search
Quantization
FP16/INT8/INT4 precision for storage optimization